Code
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['figure.figsize'] = (10, 5)
plt.style.use('fivethirtyeight')A brief introduction to the basics of machine learning, time series data, and the intersection between the two
This Time Series and Machine Learning Primer is part of Datacamp course: Machine Learning for Time Series Data in Python
This is my learning experience of data science through DataCamp
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['figure.figsize'] = (10, 5)
plt.style.use('fivethirtyeight')In this exercise, you’ll practice plotting the values of two time series without the time component.
data = pd.read_csv('dataset/data.csv', index_col=0)
data2 = pd.read_csv('dataset/data2.csv', index_col=0)# Plot the time series in each dataset
fig, axs = plt.subplots(2, 1, figsize=(10, 10));
data.iloc[:1000].plot(y='data_values', ax=axs[0]);
data2.iloc[:1000].plot(y='data_values', ax=axs[1]);
You’ll now plot both the datasets again, but with the included time stamps for each (stored in the column called “time”). Let’s see if this gives you some more context for understanding each time series data.
data = pd.read_csv('dataset/data_time.csv', index_col=0)
data2 = pd.read_csv('dataset/data_time2.csv', index_col=0)# Plot the time series in each dataset
fig, axs = plt.subplots(2, 1, figsize=(10, 10));
data.iloc[:1000].plot(x='time', y='data_values', ax=axs[0]);
data2.iloc[:1000].plot(x='time', y='data_values', ax=axs[1]);
scikit-learn expects a particular structure of data: (samples, features)data = pd.read_csv('dataset/iris.csv', index_col=0)sns.scatterplot(x='petal length (cm)', y='petal width (cm)', hue='target', data=data);
from sklearn.svm import LinearSVC
# Construct data for the model
X = data[['petal length (cm)', 'petal width (cm)']]
y = np.ravel(data[['target']])
# Fit the model
model = LinearSVC()
model.fit(X, y)LinearSVC()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
LinearSVC()
Now that you have fit your classifier, let’s use it to predict the type of flower (or class) for some newly-collected flowers.
Using the classifier you fit, you’ll predict the type of each flower.
targets = pd.read_csv('dataset/iris_target.csv', index_col=0)# Create input array
X_predict = targets[['petal length (cm)', 'petal width (cm)']]
# Predict with the model
predictions = model.predict(X_predict)
print(predictions)
# Visualize predictions and actual values
plt.scatter(X_predict['petal length (cm)'], X_predict['petal width (cm)'],
c=predictions, cmap=plt.cm.coolwarm);
plt.xlabel('petal length (cm)');
plt.ylabel('petal width (cm)');
plt.title("Predicted class values");
print("\nNote that the output of your predictions are all integers, representing that datapoint's predicted class")[2 2 2 1 1 2 2 2 2 1 2 1 1 2 1 1 2 1 2 2]
Note that the output of your predictions are all integers, representing that datapoint's predicted class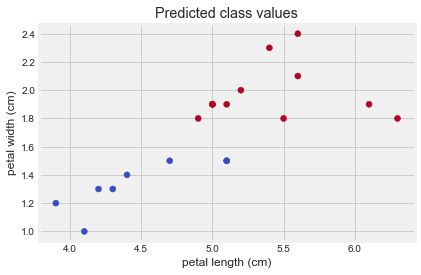
In this exercise, you’ll practice fitting a regression model using data from the Boston housing market.
boston = pd.read_csv('dataset/boston.csv', index_col=0)
boston.head()| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | B | LSTAT | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00632 | 18.0 | 2.31 | 0.0 | 0.538 | 6.575 | 65.2 | 4.0900 | 1.0 | 296.0 | 15.3 | 396.90 | 4.98 |
| 1 | 0.02731 | 0.0 | 7.07 | 0.0 | 0.469 | 6.421 | 78.9 | 4.9671 | 2.0 | 242.0 | 17.8 | 396.90 | 9.14 |
| 2 | 0.02729 | 0.0 | 7.07 | 0.0 | 0.469 | 7.185 | 61.1 | 4.9671 | 2.0 | 242.0 | 17.8 | 392.83 | 4.03 |
| 3 | 0.03237 | 0.0 | 2.18 | 0.0 | 0.458 | 6.998 | 45.8 | 6.0622 | 3.0 | 222.0 | 18.7 | 394.63 | 2.94 |
| 4 | 0.06905 | 0.0 | 2.18 | 0.0 | 0.458 | 7.147 | 54.2 | 6.0622 | 3.0 | 222.0 | 18.7 | 396.90 | 5.33 |
plt.scatter(boston['AGE'], boston['RM']);
from sklearn import linear_model
# Prepare input and output DataFrame
X = boston[['AGE']]
y = boston[['RM']]
# Fit the model
model = linear_model.LinearRegression()
model.fit(X, y)LinearRegression()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
LinearRegression()
Now that you’ve fit a model with the Boston housing data, lets see what predictions it generates on some new data. You can investigate the underlying relationship that the model has found between inputs and outputs by feeding in a range of numbers as inputs and seeing what the model predicts for each input.
new_inputs = np.array(pd.read_csv('dataset/boston_newinputs.csv', index_col=0, header=None).values)# Generate predictions with the model using those inputs
predictions = model.predict(new_inputs.reshape(-1,1))
# Visualizae the inputs and predicted values
plt.scatter(new_inputs, predictions, color='r', s=3);
plt.xlabel('inputs');
plt.ylabel('predictions');C:\Users\dghr201\AppData\Local\Programs\Python\Python39\lib\site-packages\sklearn\base.py:450: UserWarning: X does not have valid feature names, but LinearRegression was fitted with feature names
warnings.warn(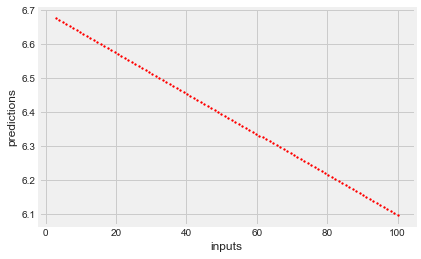
In these final exercises of this chapter, you’ll explore the two datasets you’ll use in this course.
The first is a collection of heartbeat sounds. Hearts normally have a predictable sound pattern as they beat, but some disorders can cause the heart to beat abnormally. This dataset contains a training set with labels for each type of heartbeat, and a testing set with no labels. You’ll use the testing set to validate your models.
As you have labeled data, this dataset is ideal for classification. In fact, it was originally offered as a part of a public Kaggle competition.
import librosa as lr
from glob import glob
# List all the wav files in the folder
audio_files = glob('dataset/files/*.wav')
# Read in the first audio file, create the time array
audio, sfreq = lr.load(audio_files[0])
time = np.arange(0, len(audio)) / sfreq
# Plot audio over time
fig, ax = plt.subplots();
ax.plot(time, audio)
ax.set(xlabel='Time (s)', ylabel='Sound Amplitude');
print("\nThere are several seconds of heartbeat sounds in here, though note that most of this time is silence. A common procedure in machine learning is to separate the datapoints with lots of stuff happening from the ones that don't.")
There are several seconds of heartbeat sounds in here, though note that most of this time is silence. A common procedure in machine learning is to separate the datapoints with lots of stuff happening from the ones that don't.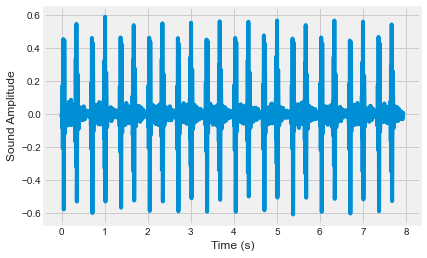
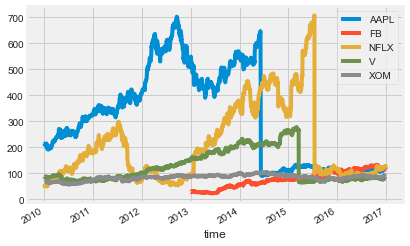
The next dataset contains information about company market value over several years of time. This is one of the most popular kind of time series data used for regression. If you can model the value of a company as it changes over time, you can make predictions about where that company will be in the future. This dataset was also originally provided as part of a public Kaggle competition.
In this exercise, you’ll plot the time series for a number of companies to get an understanding of how they are (or aren’t) related to one another.
# Read in the data
data = pd.read_csv('dataset/prices_nyse.csv', index_col=0)
# Convert the index of the DataFrame to datetime
data.index = pd.to_datetime(data.index)
print(data.head())
# Loop through each column, plot its values over time
fig, ax = plt.subplots();
for column in data.columns:
data[column].plot(ax=ax, label=column);
ax.legend();
print("\nNote that each company's value is sometimes correlated with others, and sometimes not. Also note there are a lot of 'jumps' in there - what effect do you think these jumps would have on a predictive model?") AAPL FB NFLX V XOM
time
2010-01-04 214.009998 NaN 53.479999 88.139999 69.150002
2010-01-05 214.379993 NaN 51.510001 87.129997 69.419998
2010-01-06 210.969995 NaN 53.319999 85.959999 70.019997
2010-01-07 210.580000 NaN 52.400001 86.760002 69.800003
2010-01-08 211.980005 NaN 53.300002 87.000000 69.519997
Note that each company's value is sometimes correlated with others, and sometimes not. Also note there are a lot of 'jumps' in there - what effect do you think these jumps would have on a predictive model?